Overview of HomeLending Schema Architecture
Before we begin the dive into
the details of the various schema design strategies that we'll use to
protect sensitive data in the HomeLending database, it's worth taking a "big picture" look at the schema design that we plan to implement, as shown in Figure 1.
This figure illustrates three of the four design strategies that we'll cover in this article:
The third normal form level of normalization that is applied to the schema architecture of the HomeLending database.
The introduction of the Income_Schema database object schema, to house the sensitive Borrower_Income table, and its relationship to the tables in the default database object schema (dbo).
The implementation of a linked server for the Credit_Report data.
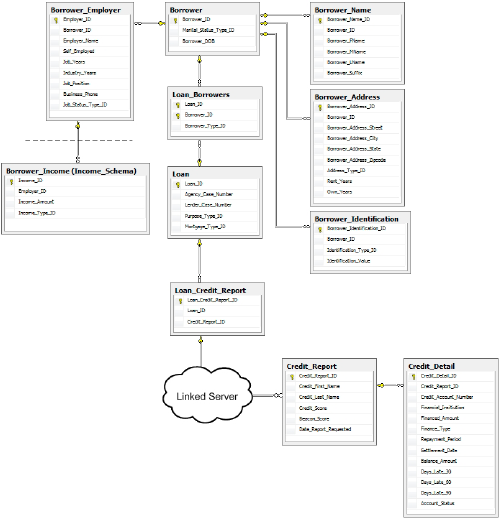
It is worth noting, in regard to the introduction of the Income_Schema
database object schema, that in reality we would probably extend this
concept, for example creating a "Borrower" database object schema for
the borrower tables rather than have all the remaining tables in the dbo schema.
The fourth strand of our strategy, not depicted in Figure 1,
is the abstraction of the database schema, using views, in order to
simplify data queries for the end user and also prevent them from
viewing unauthorized data.
Protection via Normalization
Defining the storage
structure of data is an important step in the creation of a database.
The process of breaking up a mass "lump" of data into logical and
relational collections is called normalization.
This process defines the organization of tables, their relationship to
other tables, and the columns contained within the tables. The proper
and appropriate application of normalization is a critical component in
ensuring the integrity and confidentiality of the data.
The degree to which
normalization has been applied is measured primarily by levels of
"normal form". These levels are defined by specific criteria that must
be met by the schema design. Each of these levels is cumulative. The
higher form cannot be achieved without first meeting the criteria of the
lower forms. Since the introduction of relational databases there have
been many forms of normalization developed; but the three most common
forms of normalization are first normal form, second normal form and
third normal form. Among these common forms, the separation of data into
logical groups that is possible through third normal form provides the
highest level of protection of sensitive data. Figure 2 shows a de-normalized version of Borrower information that resides in our HomeLending database.
The criteria that define the
three most common levels of normal form are described in the following
sections. In practice, the level of normalization that is targeted may
vary depending upon the intended use of the tables. A table that
contains data that will be modified regularly, such as in an on-line
transaction processing database (OLTP), will benefit from a higher level
of normalization, due to the reduction in redundant data storage within
the database. A table that contains data that is static, but heavily
read, such as an on-line analytic processing database (OLAP), will
benefit from a lower level of normalization due to the reduction of
joins required to access related data.
First Normal Form
Data should be separated into tables, each of which contains columns that are logically similar.
Each
of these tables should have a unique identifier, known as a primary
key, which represents each row and prevents duplicate rows.
The columns in the table should not contain any "repeating groups" of data.
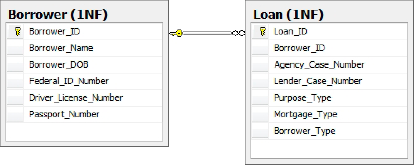
Figure 3
shows a version of the borrower information that meets the criteria for
first normal form. The loan data is stored in a separate table from the
borrower information. A single borrower record can be related to
multiple loan records. Each record contains its own primary key and the
data is not repeated across the data row.
Second Normal Form
The non-primary key
columns that are contained within the table must be dependent upon the
primary key. If the data in the table applies to multiple rows within
the table it should be moved to a separate table.
Tables contain values that are related to other tables' primary key. These values are called foreign keys.
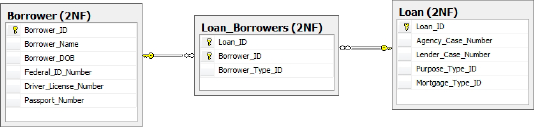
Figure 4 shows a design for the borrower information that meets the criteria for second normal form. Notice that the Borrower_Type, Purpose_Type and Mortgage_Type columns have _ID added to their names. These items are now foreign keys to reference tables. Also, the introduction of the Loan_Borrowers table allows many borrowers to be related to many loans. The movement of the borrower type to the Loan_Borrowers table allows for each borrower relationship to loans to be defined individually.
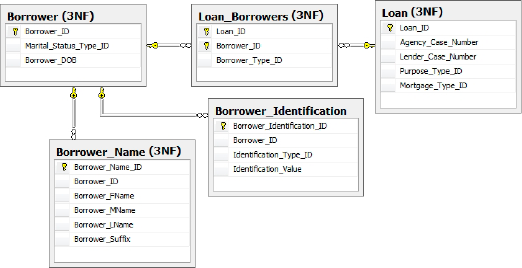
Third Normal Form
Figure 5
shows a design for the borrower information that meets the criteria for
third normal form. The borrower's federal id number, driver's license
and passport number are pulled into a Borrower_Idenitification table, as the combination of Identification_Type_ID and Identification_Value
columns. Additionally, the borrower name is pulled
out of the borrower table, allowing multiple versions of names for a
borrower such as alias and maiden names. The names have also been broken
out to their respective parts for more flexible usage.
Normalization and Data Redundancy
When a database is well
normalized, the occurrence of repeating information throughout the
database is reduced or eliminated. This, in turn, reduces or eliminates
the likelihood that data is updated in one place and not another,
thereby introducing inconsistencies. Consider, for example, a store that
sells T-shirts. This store may have many types of shirts in their
inventory, from many suppliers. If their database was not normalized
they would likely have the supplier's address in each row of their
inventory. When a supplier notifies them of a change of address they
would need to update every row that contained the old address. This
difficult task will be made worse by the fact that it is probable that
the address was recorded inconsistently throughout the database, and so
it's likely that some instances will be missed.
If their database was
normalized, the address information for each supplier would be
maintained in a single location in the database, most likely in a
"supplier address" table, related to the supplier table. This would
result in consistency in the address information, elimination of the
need to continually enter the address information, and would make the
address change process a snap.
Normalization and Data Security
For security purposes, the
reduction in data redundancy provides an environment that can be
managed in a more effective manner. Furthermore, the separation of
sensitive information from identifying information reduces the value of
the sensitive information to the potential data thief, and provides a
degree of obscurity to the casual, yet authorized, viewer.
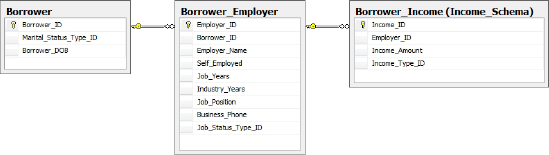
Consider the following example from our HomeLending database, illustrated in Figure 6. The Borrower table has a one-to-many relationship to the Borrower_Employer
table. This design lets us capture each employer that the borrower
lists on their application. The borrower's income data is stored in a
separate table, called Borrower_Income, and is related to the Borrower_Employer table.
As a DBA you might find yourself, one fine day, troubleshooting the Borrower_Income
table in this database. The table is opened and within it is income
information for all borrowers. Since the table has been effectively
normalized, the only data that is disclosed will be a series of rows
containing money values, each associated with a numeric foreign key,
referring to the Borrower_Employee
table. If the table were not normalized, it is likely that each piece of
income data in the table would have the borrower's name next to it,
disclosing confidential and identifying data. In addition, you could
make a fair bet that the borrower's federal tax identification number
would be there too!
Normalization and the Borrower_Identification table
Let's now take a look at the Borrower_Identification table, depicted in Figure 7, and consider its use of normalization.
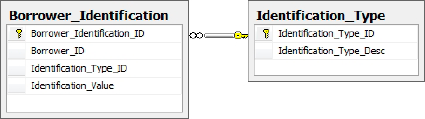
This table's design is unique in that the Identification_Value
column is used to store various values that are used to validate
identity, such as federal identification number, passport number and
driver's license number. The Identification_Type_ID column is a foreign key to a reference table called Identification_Type. It is the Identification_Type_ID column that differentiates these values for each row.
An example of the data that would be contained within the Borrower_Identification table is shown in Table 1.
Table 1. Sample data from the Borrower_Identification table.
| Borrower_ID | Identification_Type_ID | Identification_Value |
|---|
| 103 | 2 | R7KFU413243TDDIN |
| 103 | 1 | 555-08-4862 |
| 103 | 3 | 6311791792GBR6819855M297028731 |
One benefit of this column
reuse is flexibility. This design allows quick implementation of new
forms of identification validation; it simply involves creating a new
record in the Identification_Type_ID column.
Another benefit to column
reuse is the obscurity that this approach introduces to the column's
data. If the contents of this table were disclosed, the viewer would
still need to gain additional information, in this case the contents of
the Identification_Type table, as well as the contents of the Borrower table, in order to make the disclosure useful for fraudulent purposes.
Separating sensitive data
from the object to which it relates, using normalization, is a
fundamental security strategy. However, we can go even further than
that. A single SQL Server installation, also known as an instance, can
hold up to 32,767 databases. We can strategically place blocks of
sensitive data in their own databases to provide a layer of obscurity
and separation that extends to the physical data files, transaction logs
and back up files.
Querying data across
multiple databases within an instance of SQL Server requires the use of
the fully qualified object names, as demonstrated by the query in Listing 1.

Please note that the HomeLending database schema does not reflect the specific cross database architecture shown in Listing 3-1. It is offered only as an example of this approach.